数据库范式
1. 背景
最近,大学时光数据库课程中的数据库范式这几个字一直萦绕在脑海当中,久久不能消散,自然是因为当时年少,忽视了这块知识的重要性,就像是掉在了地上的番薯,当时自个也懒得弯腰将其捡起,直到三四年后的如今,是时候弯腰了
数据库范式也被称之为数据库规范化、正规化、标准化,英文称之为Database normalization,它是数据库设计的一系列原理(可以直接理解成是一套基础理论),目的在于减少数据库中的数据冗余、增进数据的一致性,这套理论是英国计算机科学家艾德加·科德(Edgar F.Codd)于1970年在他发表的论文中《关系模型的数据库系统》中提出
数据库范式发展至今,其提出的范式标准已经日益庞大,包含了以下:
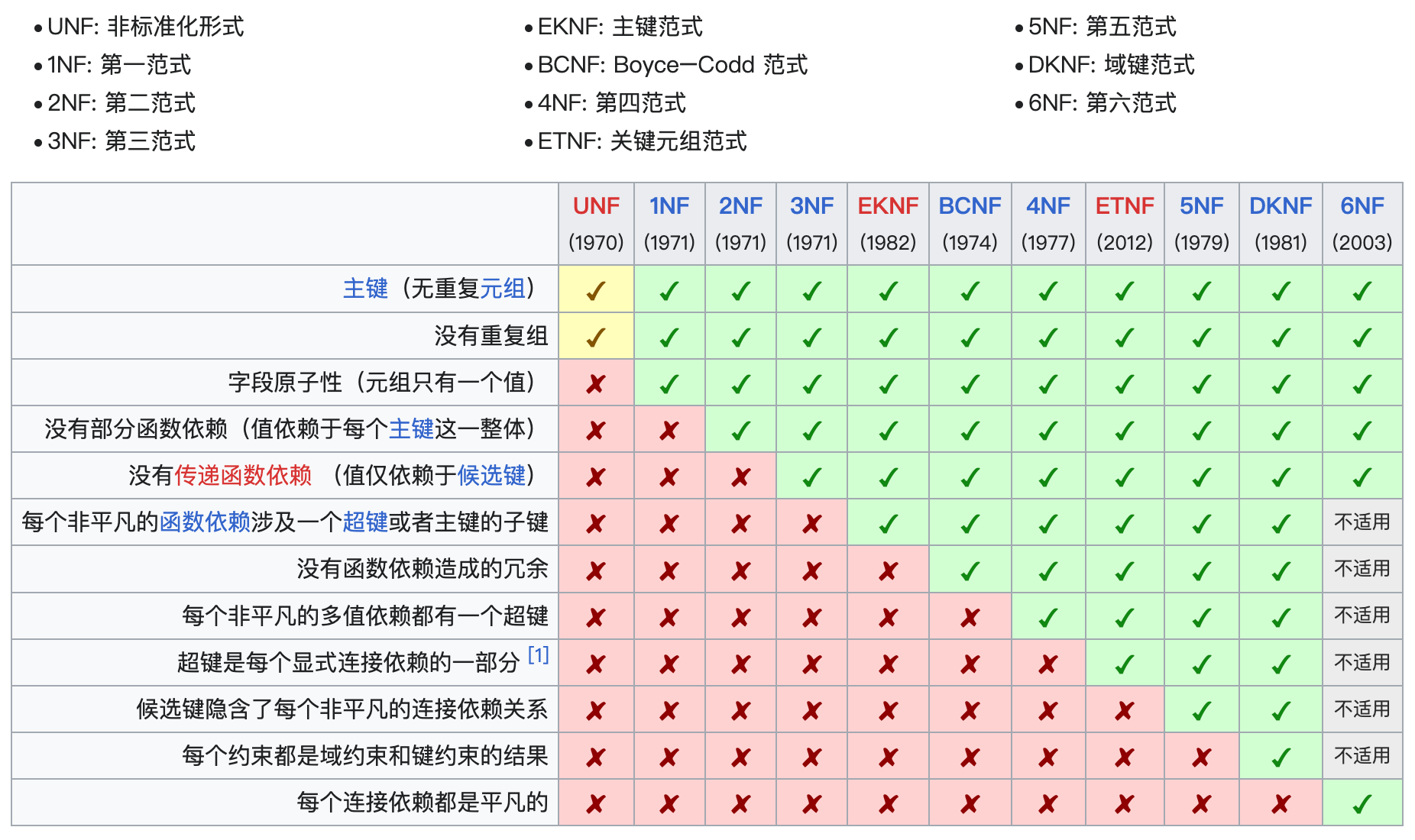
而在实际的数据库设计与应用中,通常只会参考第一范式(1NF)至第三范式(3NF),根据上图可以观察到这三个范式保证了数据的规范性和一致性,主要在于关注消除数据冗余和减少数据更新异常以及保持数据一致性,因此这仨范式实际上已经能够满足业务需求,过高的范式虽然对数据关系有更高的约束,但也会导致数据关系表增加,从而转换为数据库IO性能的增加,因此本文也会主要聚焦在第一范式至第三范式进行沉淀
范式为什么是NF结尾?
NF是Normal Form的缩写,这组词汇的中文意思是标准形式,用来表示数据库表的规范程度,而NF结尾表示的是范式的级别
2. 第一范式 - 1NF
第一范式(1NF)的准则在于需要确保表中每一列都是原子的,即每一列都只包含一个值,且不可再分,目的是消除重复数据
举一个反例,假设存在一张学生信息数据表,其中一列是联系号码,其取值可能存在多个号码(比如手机号码和电话号码),如下所示:
| id | name | contact_numbers |
|---|---|---|
| 1 | 小明 | 123-456-7890, 020-112313111 |
| 2 | 小红 | 555-123-1111, 020-1121333 |
在上述例子中,联系号码存在多种值,因此说它违反了第一范式(1NF)原则,因为这一列数据是可以进行再分的,并不是原子的,为了符合第一范式(1NF)原则,应该将这种多值的列拆分成多个原子列,如下所示:
| id | name | phone_number_1 | phone_number_2 |
|---|---|---|---|
| 1 | 小明 | 123-456-7890 | 020-112313111 |
| 2 | 小红 | 555-123-1111 | 020-1121333 |
如此一来,这张学生信息数据表中的每一列包含的值都是不可再分的,这种设计符合第一范式(1NF)的要求
业务数据表中
text类型的JSON字段列是否违反了第一范式(1NF)?第一范式要求每一列都包含的是原子值,而JSON列可以包含复杂的结构,包含嵌套的数组和对象,这种结构往往是不固定的,因此个人认为这种JSON字段列不违反第一范式(1NF)
是选择
text类型的字段来存储数据还是将JSON数据拆分成数据列、数据表取决于业务本身的复杂度,没有绝对的答案
3. 第二范式 - 2NF
第二范式(2NF)的目标是非主键数据列完全依赖于主键,而不能只依赖于主键的一部分
举一个反例,假设存在一张订单数据表,表中存在复合主键 - 订单ID与产品ID(由多个数据列组成的主键),则根据第二范式,该数据表的其他非逐渐列的值应当完全依赖于这个复合主键,而不应该只是其中的一部分,如下所示:
| order_id | product_id | product_name | product_category | product_price | quantity |
|---|---|---|---|---|---|
| 1 | 101 | 商品A | 电子产品 | 1000 | 2 |
| 2 | 102 | 商品B | 服装 | 200 | 3 |
以上反例数据表中,order_id与product_id组成了复合主键,但是数据表中的product_category产品类别这一列实际上只与复合主键中的product_id有关联,与order_id一点关系都没有,然而根据第二范式的要求,非主键列的值应当直接依赖于整个主键
解决以上反例数据表的核心问题在于需要将product产品相关信息从订单数据表中抽离出来,从而形成以下:
- 产品信息表 - product
| id | name | category | price |
|---|---|---|---|
| 101 | 商品A | 电子产品 | 1000 |
| 102 | 商品B | 服装 | 200 |
- 订单信息表 - order
| id | product_id | amount | quantity |
|---|---|---|---|
| 1 | 101 | 2000 | 2 |
| 2 | 102 | 600 | 3 |
通过以上数据表拆分,复合主键也变成了两个数据表的单一主键,产品类别字段不再依赖于复合主键(订单ID和产品ID),而是直接依赖于产品ID,满足了第二范式(2NF)的要求,一定程度上解决了数据冗余(原先数据表中,多份同类产品订单会冗余重复的产品信息)和各类写入异常
4. 第三范式 - 3NF
第三范式(3NF)要求的是数据表中的每一列都直接依赖于主键,而不是间接依赖,也就是说任何非主键列都不能依赖其他的非主键数据列,这样的规范有助于消除传递依赖,提高数据结构的规范性和一致性
以下是一个违反第三范式的反例,假设存在一张雇员信息数据表,表中包含了姓名和所属部门的信息,如下所示:
| employee_id | name | department | department_address |
|---|---|---|---|
| 1 | 小明 | 开发部 | 保利国际中心12F |
| 2 | 小红 | 销售部 | 保利国际中心13F |
在上述反例中,department_address数据列依赖于department数据列,department数据列又依赖于employee_id数据列,从而形成了传递依赖,不符合第三范式的要求
为了满足第三范式,将上述雇员表拆分为两个表,分别是雇员信息表于部门信息表,如下所示:
- 雇员信息表 - employee
| id | name | department_id |
|---|---|---|
| 1 | 小明 | 1 |
| 1 | 小红 | 2 |
- 部门信息表 - department
| id | name | address |
|---|---|---|
| 1 | 开发部 | 保利国际中心12F |
| 2 | 销售部 | 保利国际中心13F |
如此这般,部门地址直接依赖于部门ID,不再依赖于雇员ID,因此符合第三范式的要求,这种拆分有利于消除冗余
候选键是什么意思?
候选键是关系表中唯一标识数据行的一组属性列,每一个数据表可以有多个候选键,但它的值必须是唯一的,能够唯一标识数据表中的每一行,候选键通常用于确定关系表的主键,主键一般是从候选键中选择的一个,因此候选键和主键不是一个意思,更像是主键是候选键中的一个子集
完全函数依赖是什么意思?
当一个数据列完全依赖于候选键的所有属性,而不单单是依赖候选键的一部分时,就成为完全函数依赖
至此,数据库范式的基础理论设计到的三种常见类型(第一二三范式)已经复习完成,但实际业务开发的过程中,会发现完全满足范式比较困难,因为实际业务设计数据表的过程中,不可避免的会出现诸如冗余数据列这种边界情况,通常则需要工程师在规范性和性能之间做平衡做取舍,所以整体感受上来看,个人觉得数据库范式并不是生搬硬套,有些边界情况可能会打破范式,但这是可以被接受的