0. Message Queue
用于消息在传输过程中保存消息的容器,一般用于分布式系统之间进行通信
优势
- 应用解耦:系统的耦合性越高,容错性就越低,可维护性就越低,使用MQ可以使得应用间解耦,提升容错性和可维护性
- 异步提速:提升用户体验和系统吞吐量(单位时间内处理请求的数目)
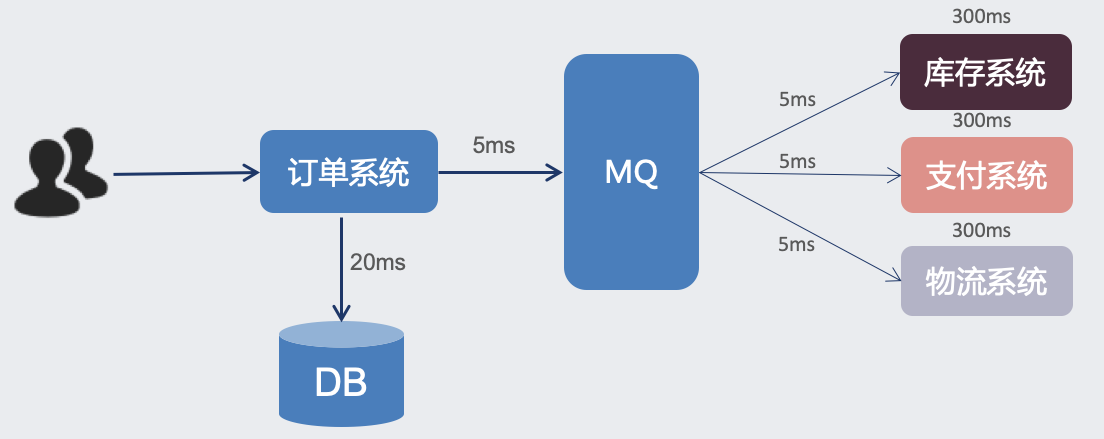
- 削峰填谷:请求量瞬间增多,大量的请求进入消息队列后进行等待,可以由应用服务端延时处理,达到削峰填谷的效果,提高系统稳定性
劣势
- 系统可用性降低:系统引入的外部依赖越多,系统的稳定性就越差,
- 系统复杂度提高:由先前的同步远程调用变更为MQ进行异步调用,同时还需要考虑消息不被丢失的情况
其他
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司 / 社区 | Rabbit | Apache | 阿里巴巴 | Apache |
| 开发语言 | Erlang | Java | Java | Scala & Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义 | 自定义协议,社区封装了HTTP协议 |
| 客户端支持语言 | 官方支持Erlang,Java,Ruby等 | Java, C, C++, Python, PHP, Perl, .NET | Java | 官方支持Java |
| 单机吞吐量 | 万级 | 万级 | 十万级 | 十万级 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 功能特性 | 并发能力强,性能极好,延时低,管理界面丰富 | 老产品,文档多,成熟度高 | 扩展性能强 | 只支持主要的MQ功能,为大数据领域准备 |
1. Mac OS RabbitMQ setup
1 | 更新源 |
安装过程中如果遇到fatal: not in a git directory\n Error: Command failed with exit 128: git异常,执行以下命令解决
1 | git config --global --add safe.directory /opt/homebrew/Library/Taps/homebrew/homebrew-core |
安装过程中如果遇到Error: No such file or directory @ rb_sysopen异常,执行以下命令解决
1 | export HOMEBREW_BOTTLE_DOMAIN='' |
随后通过http://localhost:15672访问本地RabbitMQ管理页面,界面如下
默认的账号密码均为
guest
至此,RabbitMQ安装完成
控制台角色
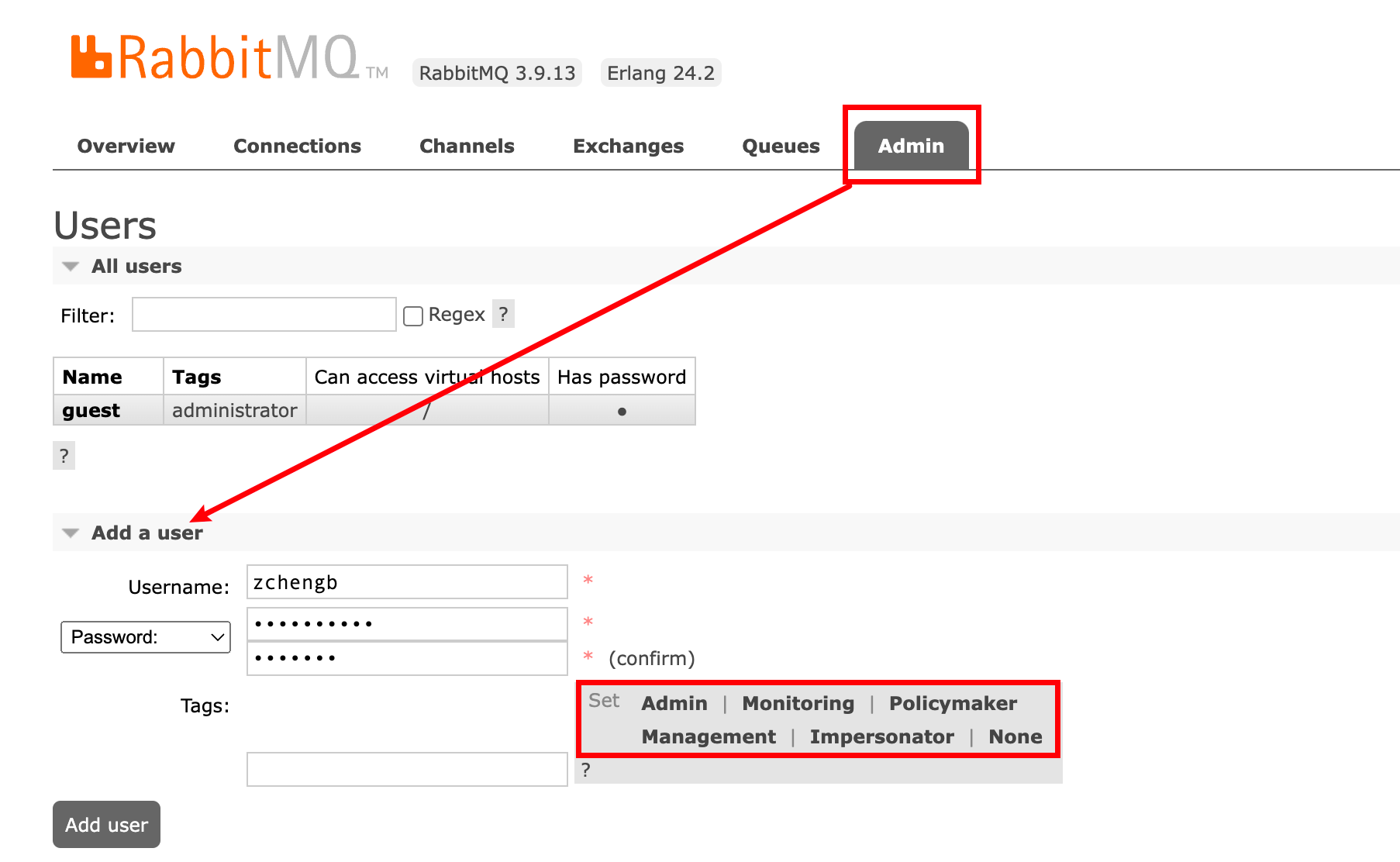
- Admin: 可登录管理控制台,可查看所有的信息,并且可以对用户,策略进行操作
- Monitoring: 可登录管理控制台,查看RabbitMQ节点的相关信息(进程数 & 内存使用情况 & 磁盘使用情况)
- Policymaker: 可登录管理控制台,同时可以对policy进行管理,但无法查看节点的相关信息
- Management: 仅可登录控制台,无法看到节点信息,也无法对策略进行管理
- Impersonator: 模拟者,无法登陆管理控制台
- None: 其他用户,无法登陆管理控制台,通常是作为普通的生产者和消费者
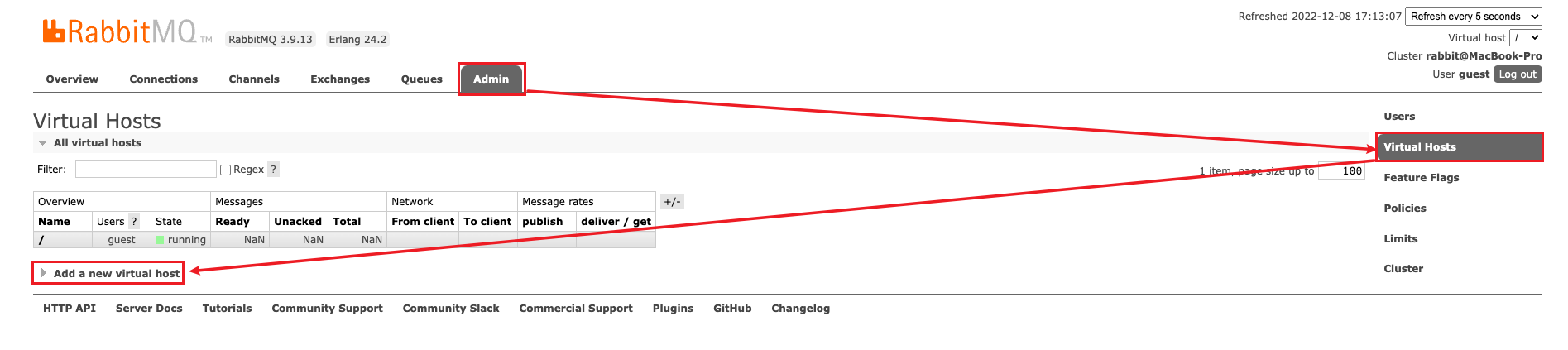
Virtual Hosts
像MySQL数据库类似的概念,可以指定用户对数据库和表的操作权限,每一个Virtual Host相当于是一个独立的RabbitMQ服务器,每个Vritual Host相当于是一个相对独立的环境,其中的exchange, queue, message无法互通,Virtual Name一般以/开头,创建入口如下
2. AMQP
Advanced Message Queuing Protocol - 高级消息队列协议
AMQP是一个网络协议,属于应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可以传递消息,并不受客户端 / 中间件不同产品或者是不同的开发语言所限制
3. 概述
2007年,Rabbit技术公司基于AMQP标准开发的RabbitMQ 1.0发布,RabbitMQ采用Erlang语言开发,Erlang语言由Ericson设计,专门为开发高并发和分布式系统的一种语言,在电信领域使用广泛
可以把RabbitMQ想象成是邮局,那么需要发送的消息则是一封封的邮件,当我们作为发送者把消息信件投递到邮局后,则可以确定这封信件最终会到收方手上,因此我们可以把RabbitMQ认为是邮局或者是邮箱或是信件派送员
而RabbitMQ与真是的邮局差异点在于,RabbitMQ不涉及信件纸张,而是把消息作为二进制数据传输 & 存储
Rabbit基础架构如下:
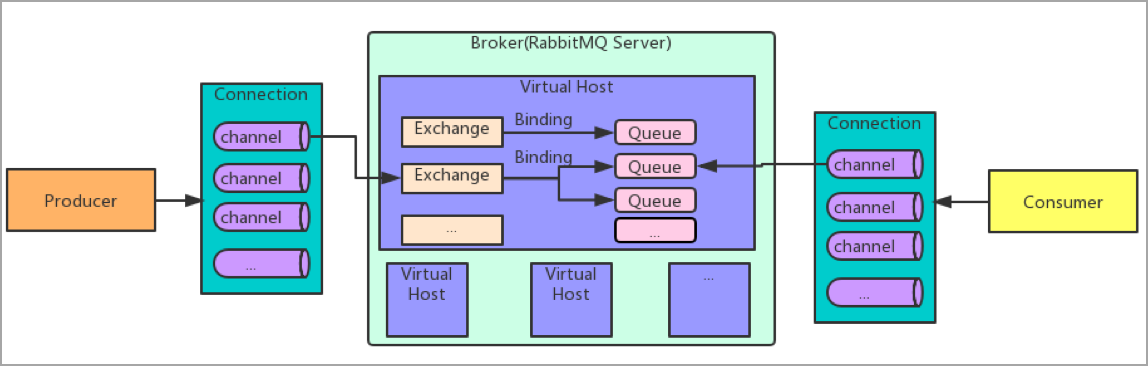
Broker
负责接收和分发消息的应用,RabbitMQ Server就是Message Broker
Virtual host
由于多租户和安全因素考虑,将AMQP的基本组件划分到一个虚拟的分组中,类似网络中namespace的概念,当多个不同的用户使用同一个RabbitMQ Server提供的服务时,可以划分出多个vhost,每个用户在自己的vhost创建exchange / queue等
Connection
publisher / consumer 和 broker之间的TCP连接
Channel
如果每一次访问RabbitMQ都建立一个Connection,在消息量大的时候建立TCP Connection的开销将是巨大的,效率也较低,Channel是在connection内部建立的逻辑连接,如果应用程序支持多线程,通常每个Thread创建单独的Channel进行通讯,AMQP method包含了channel ID帮助客户端和Message Broker识别channel,所以Channel之间是完全隔离的。Channel作为轻量级的Connection极大地减少了操作系统建立TCP Connection的开销
Exchange
message到达Broker Server时,第一个内部组件就是exchange,会根据分发规则,匹配查询表中的routing key,分发消息到queue中,常用的类型有: direct, topic, fanout
只负责消息的转发,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,消息则会丢失
Queue
消息最终被送到这里等待consumer取走
Binding
exchange和queue之间的虚拟连接,binding中可以包含routing key,Binding信息被保存到exchange中的查询表中,用于message的分发依据
4. 工作方式
示例代码中需要提前引入依赖:
com.rabbitmq:amqp-client:5.16.0
a. Hello World
即一个生产者对应一个消费者

1 | public class Sender { |
b. Work Queues
消息由多个消费者处理,与Hello World不同的是,Work Queues由多个消费者进行消息的处理
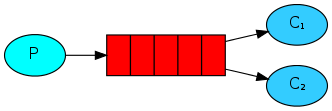
下方代码示例中,将由输入的.数量来控制消息的处理时间,并基于此开启多个WorkQueueReceiver进行消息的消费
1 | public class WorkQueueSender { |
默认情况下,RabbitMQ采用平均分配的方式来确保每个消费者都能处理平均数量的消息,称之为round-robin算法
Message acknowledgment
官方文档链接:https://www.rabbitmq.com/tutorials/tutorial-two-java.html
在默认情况下,RabbitMQ在将消息交递给消费者后,就会将其标记为删除,但如果消费者在处理过程中发生异常,实际上并未处理成功,则会造成脏数据,因此为了避免消息异常导致的丢失情况,RabbitMQ提供了消息确认功能,只有当消息被接收且回复ACK确认后,RabbitMQ才会做删除操作,如果消息长时间(默认时间30分钟)未回复ACK确认,则RabbitMQ便会将这条消息重新排入队列中继续等待处理
ACK机制可以在代码中通过channel.basicQos(1);配置过滤(作用于同一时间内只获取1条未标记为ACKED的消息),并在消费时把autoAck标识配置更改为false,消息的消费入口为以下
1 | channel.basicConsume(TASK_QUEUE_NAME, autoAck, deliverCallback, consumerTag -> { }); |
同时需要在处理完毕消息后,回复ACK标识,示例代码为以下(可放入final块中)
1 | channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false); |
这个处理过程中还有一个视野盲区,那就是如果消费者在处理完成后忘记回复ACK,可能会造成大量内存占用,并且会在确认超时后重新分配消费者,遇到上述这种情况一般则需要手动进行修复与排查,可以通过rabbitmqctl打印出messages_unacknowledged的所有消息
1 | sudo rabbitmqctl list_queues name message_ready messages_unackonwledged |
Message Durability
通过Message acknowledgment机制我们可以保证消费者中途异常或崩溃的情况下,Server端的消息不会丢失,但如果RabbitMQ Server宕机了,在默认情况下已有的所有消息依然会丢失,可以通过durable标记来确保消息持久化,如下所示
1 | channel.queueDeclare(QUEUE_NAME, durable, false, false, null) |
但上述方式对已存在的消息队列来讲并不会生效,因为RabbitMQ不允许重新定义已存在的消息队列,并且会返回异常,它只针对新创建的消息队列有效
针对已存在的消息队列,需要做持久化,则快速的解决方案是使用上述方法重新定义一个新的消息队列,同时在发送消息的时候需要带有**持久化属性(MessageProperties.PERSISTENT_TEXT_PLAIN)**的标识,如下所示
1 | channel.basicPublish("", QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes()) |
以上方式的消息持久化并不能完全保证消息不丢失,只是相当于告诉RabbitMQ需要将消息存储到磁盘中,那么实际上RabbitMQ会有一个短暂的时间接收了消息但是还没有保存它,可能只是存储在了缓存中但还未真正写入磁盘,因此这种默认的持久化方式并不完美,但对于大多数业务场景来说,已经能够满足了,那么如果我们需要一个更加完美的机制来保证持久化,可以使用publisher confirms
Fail dispatch
假设存在2个消费者A与B,那么采用这种工作方式(Work Queue)则会将消息按照奇偶顺序派发,如果消费者A处理消息需要大量的耗时,而消费者B处理消息可以很快,那么这种情况下的消息发放方式则会显得十分不公平,因此可以通过channel.basicQos(1)来设置并高数RabbitMQ不要同时派发大于1条消息给同一消费者,换个说法,这个配置会在消费者B完成消息处理后立即派发新的消息,而不是按照原来的奇偶顺序派发消息
如果所有的消费者一直位于处理消息的情况,则需要考虑是否需要新增更多的消费者或采取一些其他的策略
c. Publish / Subscribe
消息推送 / 订阅模式,一条消息将推送给多个消费者,在这个工作模型中,消息则是先推送给exchange,由exchange再根据消息中附带的参数标识(routingKey)推送给指定的消息队列
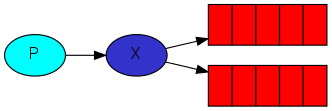
以下代码将实现一个日志记录的推送,并配合exchange由指定的消息队列接收,其中EmitLog作为日志发送者,ReceiveLogs则是作为日志消费者,ReceiveLogs中的消息队列采用的是一个临时队列
1 | public class EmitLog { |
Nameless exchange
在前边部分的工作模式介绍中,未涉及到exchange部分,但仍然能够发送消息到队列中,是因为使用的是默认的exchange,如下所示,其中空字符串(“”)则表示的是exchange的名称,这种exchange name为空或无exchange name的消息路由规则将直接采用routing key作为消息队列名称进行指定投放
1 | channel.basicPublish("", QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes()); |
Temporary queues
如果需要一个临时队列,在Java中可以通过无参的queueDeclare()方法进行声明,则会由Rabbit Server创建一个随机名称的消息队列,这个临时队列会在断开连接时自动删除其内部的消息
Bindings
通过Bindings可以准确地知道exchange应该将哪些routing key推送给哪个消息队列,而在Java中可以通过以下进行Bindings的设定
1 | channel.queueBind(queueName, exchangeName, routingKey); |
Binding是exchange和queue之间的联系,可以简单地理解成是通过binding就能够使得exchange明白哪些类型的消息是哪些消息队列感兴趣的
其中额外的参数routingKey在exchange类型为fanout时,会默认被忽略
d. Routing
Routing模式要求队列在绑定交换机时要指定Routing Key,消息会根据其转发到符合Routing Key的队列
路由模式可以按照exchange与queue之间的binding准确进行消息的分发,但前提是需要确保exchange的类型是direct而不是fanout,如下所示是对系统日志进行三个层次级别的区分,分别为orange, black, green,配合direct exchange实现不同的消息队列专注于收集不同级别的系统日志
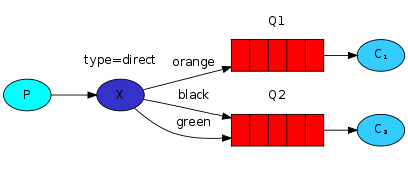
其中X作为direct类型的exchange会按照binding的不同将消息投递至Q1队列或Q2队列,其他的消息则将会被丢失
而关于将exchange声明为direct类型,则可以通过以下Java方法实现
1 | channel.exchangeDeclare(EXCHANGE_NAME, "direct"); |
e. Topic
与Routing 不的是,Topic Exchange在接收消息时带有的Routing Key必须是由dot分隔的词组,且最大长度是255字节, 比如stock.usd.nyse,而它的好处体现在使用Binding时,可以配合以下两个通配符使用,从而一次筛选绑定多个消息队列
*: 可以匹配任意一个准确的单词#: 可以匹配任意1个以上准确的词组