399. 除法求值
1. 题目
给你一个变量对数组 equations 和一个实数值数组 values 作为已知条件,其中 equations[i] = [Ai, Bi] 和 values[i] 共同表示等式 Ai / Bi = values[i] 。每个 Ai 或 Bi 是一个表示单个变量的字符串。
另有一些以数组 queries 表示的问题,其中 queries[j] = [Cj, Dj] 表示第 j 个问题,请你根据已知条件找出 Cj / Dj = ? 的结果作为答案。
返回 所有问题的答案 。如果存在某个无法确定的答案,则用 -1.0 替代这个答案。如果问题中出现了给定的已知条件中没有出现的字符串,也需要用 -1.0 替代这个答案。
注意:输入总是有效的。你可以假设除法运算中不会出现除数为 0 的情况,且不存在任何矛盾的结果。
注意:未在等式列表中出现的变量是未定义的,因此无法确定它们的答案。
示例 1:
1 | 输入:equations = [["a","b"],["b","c"]], values = [2.0,3.0], queries = [["a","c"],["b","a"],["a","e"],["a","a"],["x","x"]] |
示例 2:
1 | 输入:equations = [["a","b"],["b","c"],["bc","cd"]], values = [1.5,2.5,5.0], queries = [["a","c"],["c","b"],["bc","cd"],["cd","bc"]] |
示例 3:
1 | 输入:equations = [["a","b"]], values = [0.5], queries = [["a","b"],["b","a"],["a","c"],["x","y"]] |
提示:
1 <= equations.length <= 20equations[i].length == 21 <= Ai.length, Bi.length <= 5values.length == equations.length0.0 < values[i] <= 20.01 <= queries.length <= 20queries[i].length == 21 <= Cj.length, Dj.length <= 5Ai, Bi, Cj, Dj由小写英文字母与数字组成
2. 思路
- 并查集(不相交集合)用于处理动态连通性问题,其中一个应用就是求解「最小生成树」的Kruskal算法
- 并查集支持查询(find)和合并(union)两个关键的操作,同时它只回答两个节点是否在同一个连通分量重,并不回答路径问题
- 并差集的常见设计思想是把同一个连通分量重的节点组织成一个树形结构
- 已知题目要求按照已知的连通权重计算出不同节点之间的值,而将不同变量转化为相同变量的倍数,进行标准统一,则可解决不同节点之间计算值的问题
- 如已知
a / b = 2.0, b / c = 3.0,则可对应转化为a / c = 2b / c = 6.0,对应b / a = b / 2b = 1 / 2 = 0.5 - 因此根据已知,可以将题目给出的信息比如
a -(2.0)-> b -(3.0)-> c对应转化为a -(6.0)-> c <-(3.0)- b - 对应使用并查集的过程中,字母采用整数型ID代表,同时初始化权重量
weights来表示系数,同时在遍历的过程中,将每一组连通量进行union操作,如下所示:
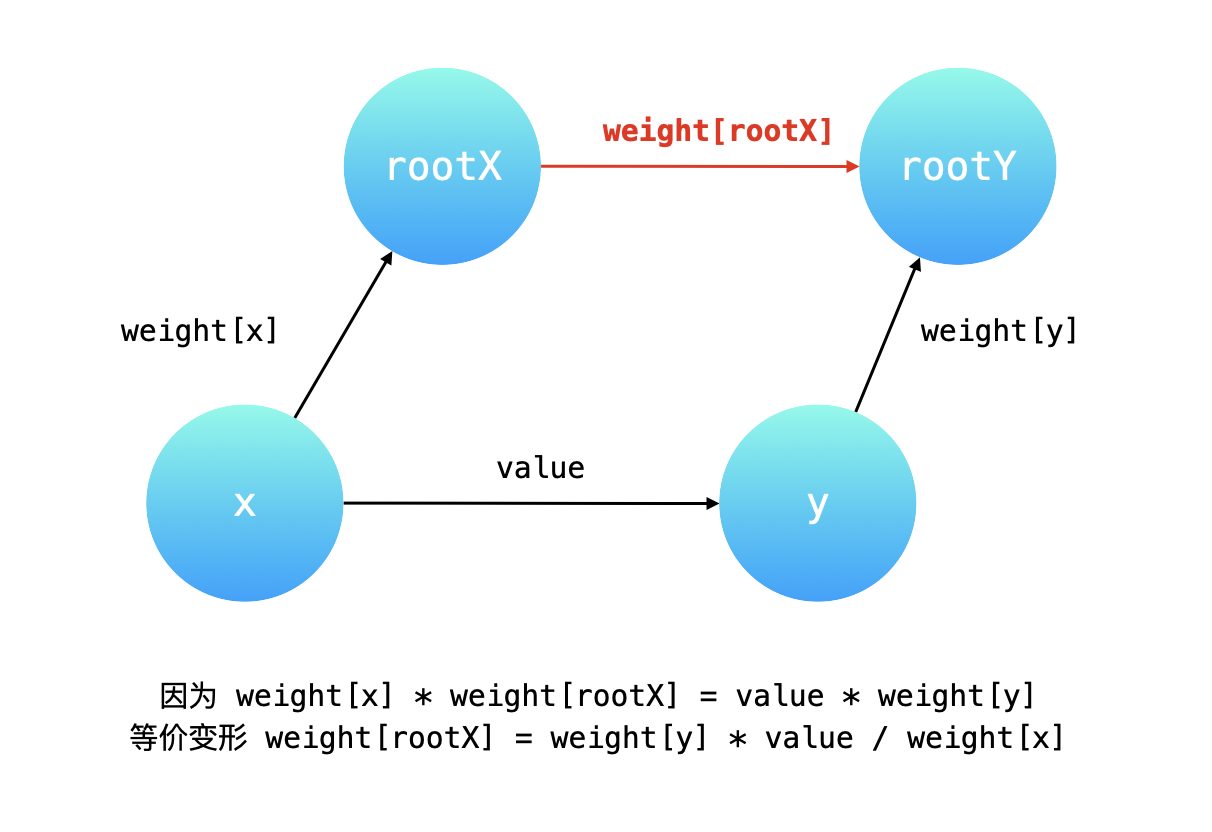
- 完成所有边的合并后,通过并查集查找
find来确认是否能够获取对应queries数组的除法求值,如果无法获取到,则直接返回-1.0结果 - 两个节点是否连通意味着是否能够有标准的变量统一可以进行计算,如果连通(通过节点的
parent判断父节点是否一致可以判断连通性),则可直接进行queries除法求值
3. 代码
1 | class Solution { |
4. 复杂度
时间复杂度:
O((N+Q)logA)- 构建并查集
O(NlogA),这里 N 为输入方程 equations 的长度,每一次执行合并操作的时间复杂度是O(logA),这里 A 是 equations 里不同字符的个数 - 查询并查集
O(QlogA),这里 Q 为查询数组 queries 的长度,每一次查询时执行「路径压缩」的时间复杂度是O(logA)
- 构建并查集
空间复杂度:
O(n)